
From Calibration to Semantics: A Stereo Perception Stack That Stays Aligned Over Cobblestone
Autonomous systems need to know where things are: the distance to every obstacle in front of them. And they need it from hardware that survives shock, vibration, and heat. The usual answer is LiDAR, at the usual cost: a sparse scatter of returns, a power-and-cooling budget, and a sensor that still has to be fused with a camera before it can tell a curb from a pedestrian.
NODAR's Hammerhead takes a different path. It turns an ordinary pair of cameras into a dense, metric 3D sensor, with depth at every pixel in real time on embedded hardware. No moving parts, no second modality, no datacenter. This post is a closer look at that depth, and what happens when we run semantic segmentation on top, so every distance also carries a label.
Why This Is Hard
Stereo gets distance from correspondence: for a point in the left image, find the same point in the right, and the sideways shift between them (the disparity) gives the depth. To search for that match, the matcher needs to know exactly how the two cameras are aligned relative to each other. That geometry tells it which row to look at.
And the geometry won't sit still. Mount a camera pair on a vehicle, and the first rough road twists it by fractions of a degree, through vibration, thermal expansion, and chassis flex. Now the matcher searches the wrong place, locks onto the wrong pixel, and the distance comes back wrong by meters. It's why a stereo rig calibrated once at the factory drifts out of spec the moment it meets real terrain.
Hammerhead closes that gap with real-time autocalibration, solving the stereo extrinsics every frame, so the match stays honest no matter how the rig shakes and heats. A dense matcher then computes a metric distance at essentially every pixel: a depth map as detailed as the camera image.
The Architecture
We ran Hammerhead on a NODAR HDK NDR-HDK-2.0-100-30-A, a 30° horizontal-FOV stereo pair, with everything executing on the onboard Jetson Orin AGX: autocalibration, stereo matching, and a dense per-pixel disparity map that lifts any pixel into metric 3D.
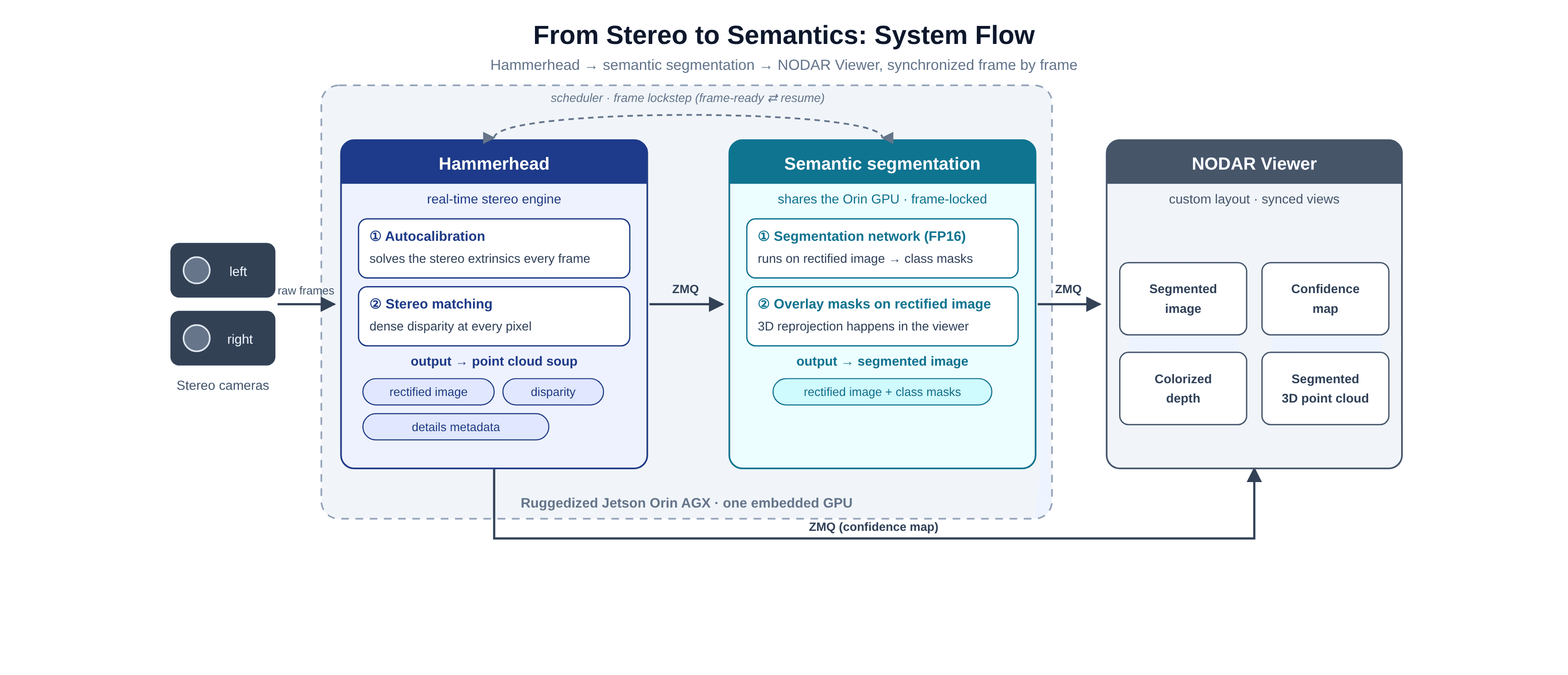
Alongside it, we ran an off-the-shelf semantic segmentation network, compiled to run in FP16, live on the same Orin, sharing one embedded GPU with the stereo pipeline in real time. That sharing is the hard part, handled by a scheduler that interlocks the two frame by frame: Hammerhead hands off a frame, the segmentation network runs on it, then Hammerhead advances. No dropped frames, and depth and labels come from the exact same instant, a direct readout of Hammerhead's geometry rather than a separate estimate.
For the scene, we picked a punishing one: a drive over cobblestone through a cluttered urban work zone in Berlin. Cobblestone is close to a worst case for stereo, since every stone jolts the rig with the kind of vibration that knocks a fixed pair out of calibration. The work zone adds clutter: an excavator with its arm swung over the lane, a road worker beside it, parked cars, traffic lights, and red barriers pinching the road. If autocalibration can hold this scene together, it can hold anything we'd meet on the road.
What Hammerhead Returned
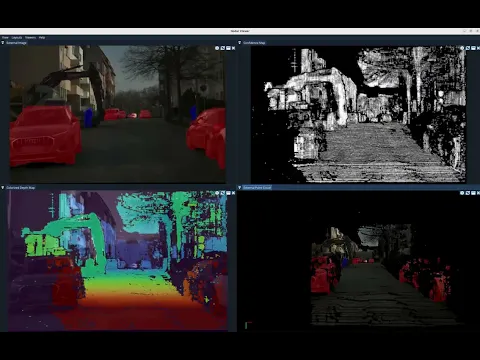
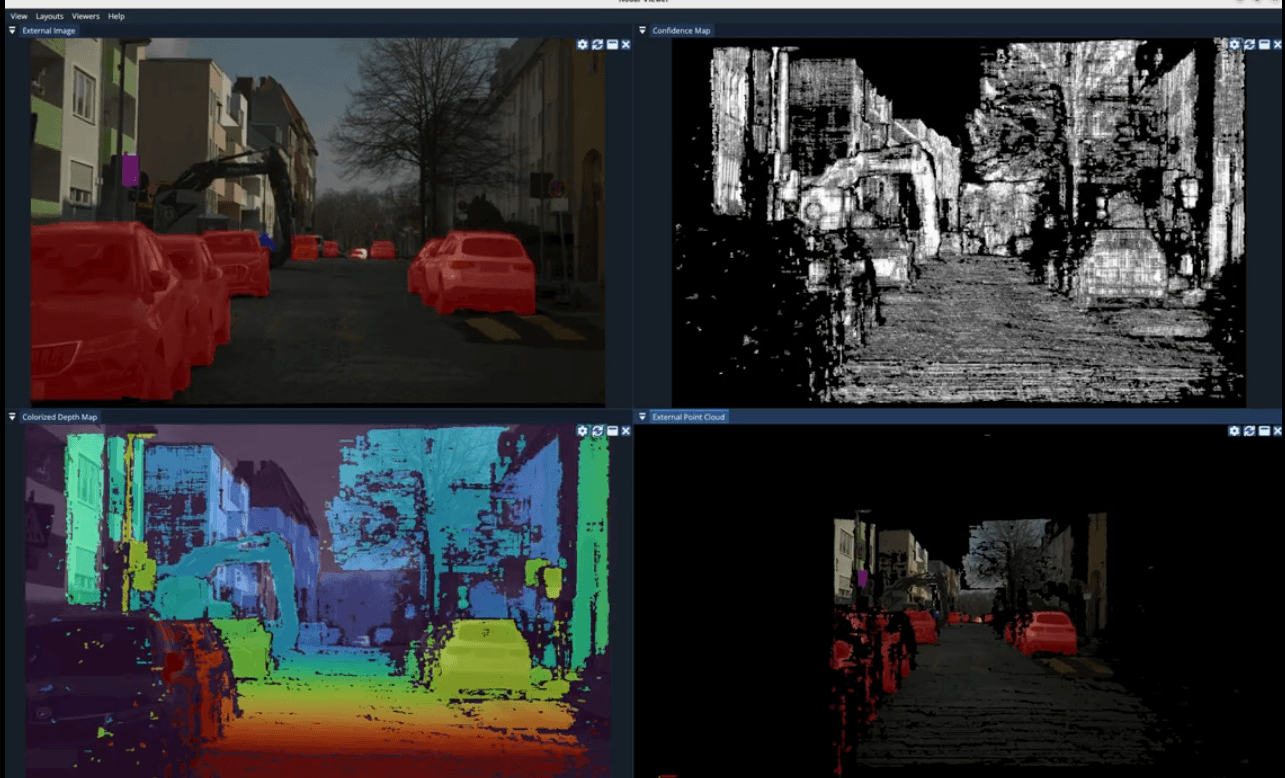
The run streams four synchronized views from the same instant: the rectified image with segmentation overlaid, a stereo confidence map, a colorized depth map, and a 3D point cloud.
The depth map reads cleanly from near to far: the road sweeps from warm (close) to cool (distant), facades and trees resolve coherently, and objects stand out at their true ranges. It held as the cobblestone hammered the rig, with no smearing or collapse into noise.
The confidence map says it directly: bright where the matcher found a high-confidence correspondence, dark where it didn't. It stays dense and bright even when the cobblestone is at its worst. That density under heavy vibration is the clearest sign that autocalibration is holding.
The segmentation overlay uses a fixed color per class: vehicles in red, people in blue, and traffic lights in magenta. The same labeled pixels then stand up in the point cloud at true scale and bearing.
Why This Matters
The teams this is for are the ones LiDAR underserves: maritime and defense platforms that need long-range depth from rugged, passive sensors, and off-road and industrial autonomy, where vibration shakes a fixed stereo rig out of calibration. They want the world's geometry at metric scale without a second modality to fuse, which is exactly what Hammerhead delivers from a camera pair.
What's new here isn't the segmentation. It's that the depth survived cobblestone-grade vibration while a full perception network ran concurrently on the same Orin, co-scheduled so neither starves. Those are the two failures that have kept camera stereo out of the field: depth that breaks on rough roads, and edge GPUs too small to host stereo and perception at once. Both held. And because the depth is dense and per-pixel, the same arrangement is useful for free-space estimation and tracking, all from a single depth map with no extra sensor.
Where This Goes Next
The depth is the constant, and everything else is built on it. This run shows the foundation already carrying a real perception load, live and in lockstep, on a single embedded GPU. From here, the work is application-specific: pushing range, tuning for an environment, and stacking the perception layers a customer needs onto the same Orin. The hard problems are already solved: depth from passive cameras, self-calibration that survives a rough road, and a real-time segmentation network on the same GPU.